GZIP: Galaxy morphology classification by zip algorithm
Even before the identification of galaxies as stellar systems, astronomers have classified them based on their visual appearance. Galaxies in the local universe can organized in a sequence of morphologies (e.g. the Hubble sequence) which must be the result of the specific processes that originated them.
The relative roles over cosmic time of processes such as the merging of dark matter haloes, dissipation, starburst, feedback, active galactic nuclei (AGN) activity, etc., however, remain largely conjectural, in particular concerning the establishment of morphological differentiation in the galaxy. Therefore, morphological analyses and studies of the evolution of galaxies with cosmic time give an important insight on how the matter aggregated into the structures that we see today.

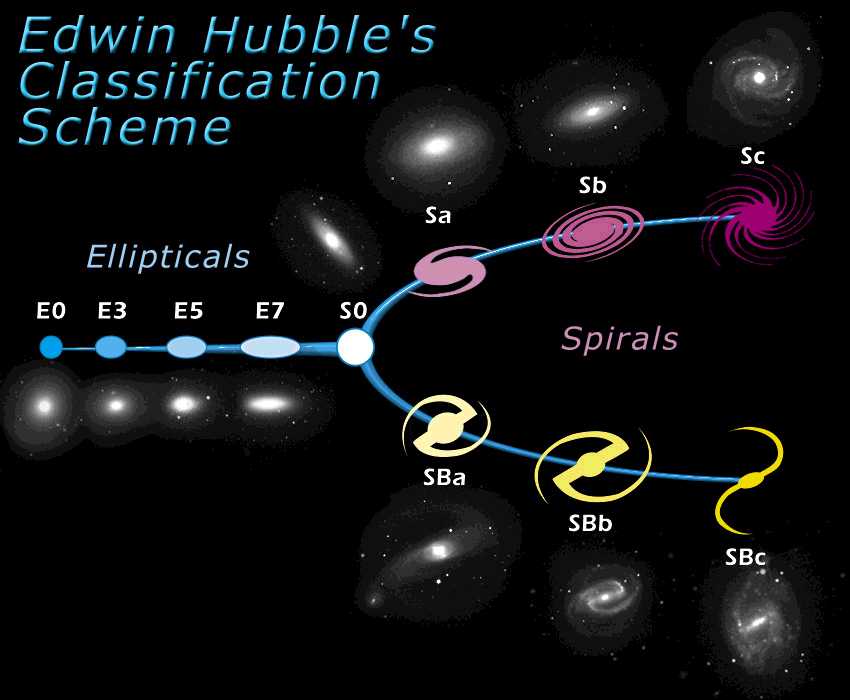
Fig 1.
In the last few decades, several methods have been applied to identify and classify the morphology of galaxies. The most recent developments range from highly refined neural network to Principal Component or Fourier Analysis, Shapelet etc. Since one can measure an almost limitless number of parameters to describe a galaxy, a standard approach is to reduce the dimensionality of parameter space. PCA, Fisher Matrix and other techniques provide a linear method of reducing the dimensionality of the parameter space.
However galaxy parameters are in general correlated in non-linear ways, thus a non-linear approach may be more appropriate. Various methods exist, including non-linear PCA, Information Bottleneck and ANN. Over the last few years, non-parametric approaches have been developed by several authors: the most used ones are the concentration ( C ) parameter (roughly correlates with the Sercic index and the B/D ratio), the asymmetry ( A ) and the clumpiness ( S ) (the degree of “patchiness” of galaxy).
The best methods among these accomplish for a successful rate around 90% for classification of galaxies in 3 main classes : Ellipticals,Spirals and Irregulars
We have studied a novel method for automated morphological classification of galaxies.
The method is based on data-compression techniques which allows to define a suitable measure of remoteness of two sequences. The method has been described and applied for language recognition. The compression code used is a LZSS-like algorithm, a so called dictionary methods.
It works selecting strings of symbols and encoding each string as a token using a dictionary and this is the way to remove the redundancy from the input stream.
The method gives a way to measure the so called relative entropy between two input data stream,
i.e. a measure of the statistical remoteness between two sequences of symbols.
The concept is simple: considering two sequence A and B. The compression algorithm applied to A will be able to encode it almost optimally. In other words, it will built a convenient dictionary to encode the sequence A . Such an optimal coding will not be optimal for the other sequence B. It is however possible to use the optimal code for A to encoding the sequence B. The resulting output data stream will not be shortest possible, but it will provide a coding anyhow of B.
Now we can measure the so called entropy per character of the two sequences A and B using only the optimal code for A. The entropy per character is a measure of the bits needed to encode the sequence using the dictionary extracted by the analysis of A. Then we can measure the entropy per character of B using instead an optimal code for itself.
In this way we have two measures: the entropy per character of B using the optimal code for A and the same quantity using an optimal code for B.
The difference between these two values is then the relative entropy, or a measure of the statistical remoteness between the two distributions.
Coming to the galaxy automatic classification, if we intend to use the same method, we face to the problem to obtain a sequence of symbols from a bi-dimensional picture of the galaxy. The approach we choose is that to measure the local curvature of the isophoto contours (i.e. contours of the same luminosity) in the raw picture.
The corresponding sequence of values as function of angular coordinate along the isophoto, will provide the sequence we intend to process with the previous compression technique.
A galaxy and a template will give two different sequences we will process with the compression algorithm.
Repeating the procedure for the different template (as for the different known languages) it will give different measures of relative entropy.
The morphology class of the galaxy is the same of the template for which we measure the smallest relative entropy.

Fig 2.

The study is currently in progress. The first results we got seems to show a great rate of successful identifications (around 92%) without any optimization of the method. In the figure 2, a sample of the identification matches performed by the method
References:
[1] M.Montuori, G.Rodighiero, A.Baldassarri, A.Cassata “GZIP: a novel algorithm for galaxy morphological classification” in preparation

